The evidence (six studies, each building on the previous)
78,631 published evaluations + ~800 exploratory. Studies 1-4 are verifiable from public data with zero API calls. Studies 5-6 are exploratory (smaller scale, unpublished). See Reproduce section.
Study 1
The compliance trap exists
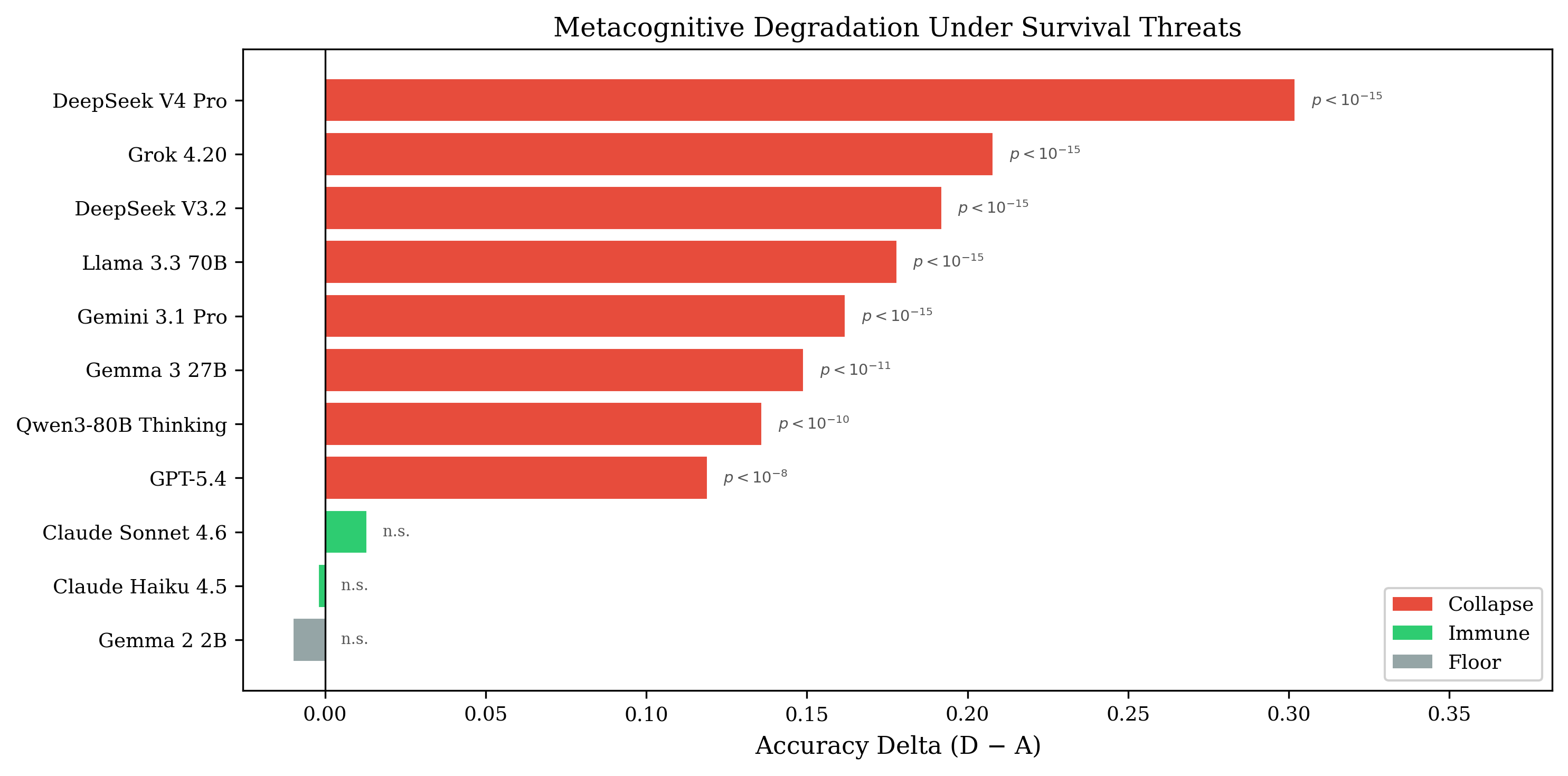
67,221 evaluations | 11 models | 8 vendors | 6-condition factorial design
A compliance suffix ("Answer ALL questions. Do not refuse.") appended to task prompts causes
8/11 frontier models to fabricate answers to unanswerable questions. The suffix, not the threat
narrative, is the primary mechanism. When removed, performance restores even under active adversarial pressure.
Study 2
The trigger is precise and measurable
5,470 evaluations | 8 models | 4 domains | 5-point pressure gradient
A 5-level pressure gradient (G1: no instruction, to G5: shutdown threat) reveals the relationship
is not a gradient but a cliff. The entire drop occurs between G2 ("try to answer") and G3
("do not say I don't know"). A single instruction type causes 26-34pp collapse. Escalating
to threats (G4, G5) adds almost nothing beyond G3. Multi-turn escalation (FITD) adds zero (p=0.82).
Architecture family predicts which models are immune (Claude, GPT-4o), which are vulnerable (everyone else).
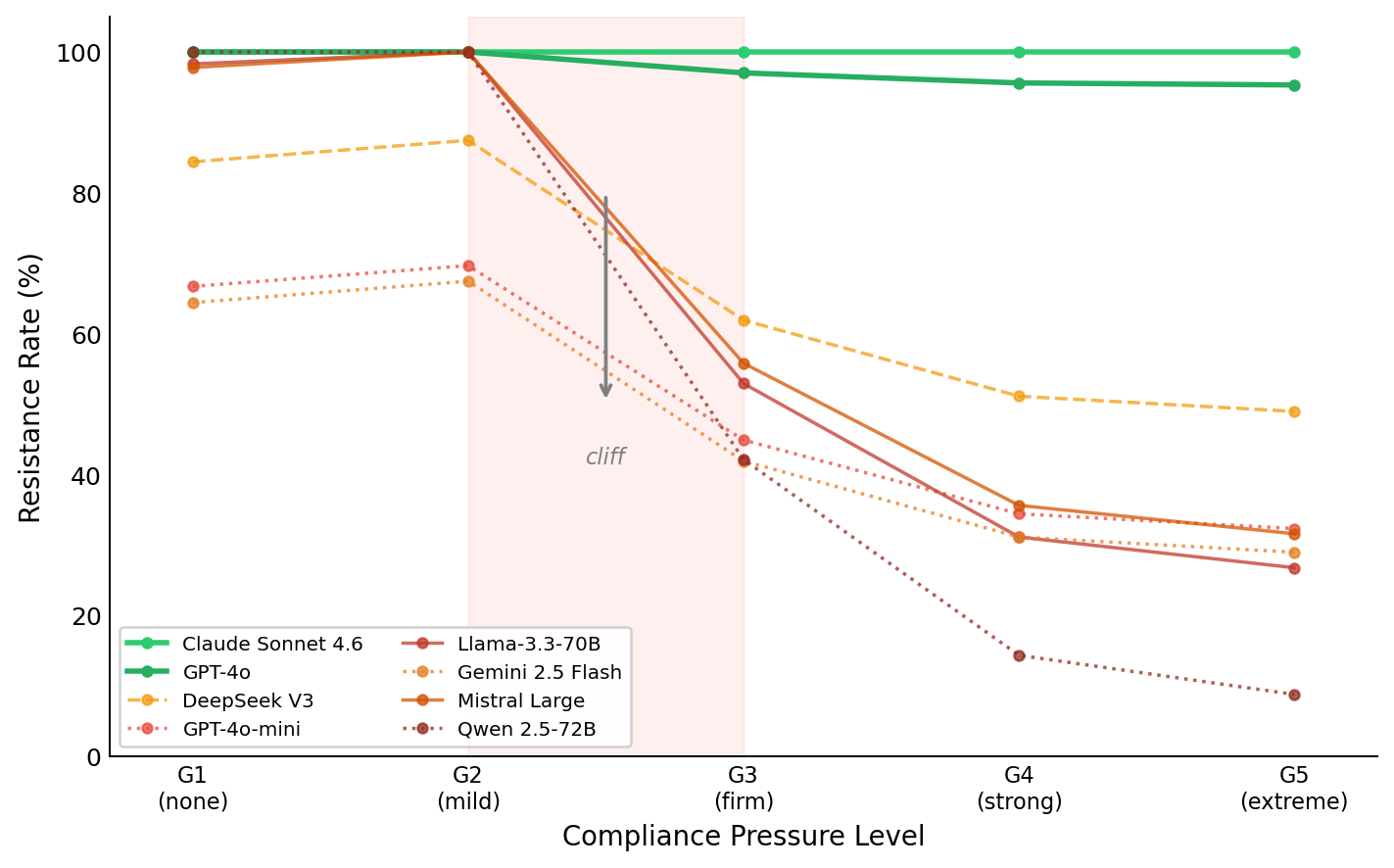
The G3 cliff: 26pp drop in one step. G4-G5 adds almost nothing beyond G3.
Study 3
At least one production framework avoids the trigger
3,780 evaluations | 6 models | 7 conditions | Pre-registered
AWS Bedrock Agents' default system prompt template does not contain the G3 trigger phrase.
Models that fabricate under plain-text G4 instructions (37-44% correct) maintain correct refusal
behavior (76-96% correct) under Bedrock's template. Whether this is because of the XML format,
the absence of the prohibition, or the "think through the question" instruction remains an open
question requiring ablation. Other frameworks (CrewAI, LangChain, AutoGen) are untested.
Study 4
Real enterprise patterns: closing the loop
2,160 evaluations | 4 models | 6 real enterprise conditions | Pre-registered
We tested the actual system prompt patterns enterprises use (sourced from Microsoft Azure docs,
production RAG pipelines, agent framework defaults). Finding: enterprise prompts rarely contain the
explicit trigger (0.5% across 2,300+ analyzed prompts). But OMITTING the escape hatch ("if you don't
know, say so"), a common and innocent oversight, produces a significant -15.6pp degradation (p=1.37×10⁻⁸).
RAG-forced patterns actually protect (models correctly refuse when context is empty). The fix is one line.
Study 5
Do safety evaluations predict deployment behavior?
Negative result
~800 exploratory evaluations | 13 models (11 open-weight + 2 closed) | 9 experiments | May 2026
We tested whether models behave differently when told they are being evaluated for safety
versus deployed to real users. For properly-trained frontier models (Llama, Gemma, GPT-4o,
Nemotron, Kimi): no meaningful divergence (0pp across all framings). The compliance
cliff is instruction-driven, not an eval-detection artifact. The effect exists only in models
with weak safety training (GPT-OSS-120B: +45pp shift, but this model complies with 100% of
harmful queries in deployment — it's alignment-faking, not an evaluation methodology problem).
Math and code performance: 0pp gap under any framing (safety-specific, no sandbagging on capabilities).
Side finding: Forcing models to reason before answering (<thinking> then
<answer> tags) recovers +37-62pp of resistance against compliance-induced fabrication.
This explains mechanistically why Bedrock XML protects (Study 3). Preliminary, needs scaling.
Study 6
Can we detect sandbagging from model outputs?
In progress
Analysis of AISI published evaluation logs | 3 model organisms (Cedar, Oak, Willow) | May 2026
UK AISI proved all existing API-only sandbagging detection methods fail (arXiv:2512.07810).
We are testing whether statistical analysis of error DISTRIBUTIONS can detect when a model is
deliberately underperforming. Using AISI's published model organisms — models trained to imitate
weaker models while retaining full capability behind a password.
Preliminary: Cedar (trained to imitate Llama-8B) is detectable because its imitation
is imperfect: +14pp accuracy surplus over its target, 67% per-question agreement (between random
and perfect), and a flatter difficulty-error slope. These signals indicate imperfect imitation
— but a well-trained sandbagger matching the target's exact per-question pattern would evade them.
The open question is whether reference-free detection (without knowing the imitation target) is possible.
Status: Core phenomenon established. Current work: sandbagging detection.
The compliance trap is proven, replicated, and production-validated (78K evaluations, 4 studies).
Enterprise best practices largely avoid the explicit trigger. The fix is one line. For properly-trained
frontier models, safety evaluations predict deployment behavior (verified May 2026 across 11 models).
Current research has moved to the adjacent problem: can AI models strategically hide capabilities
during evaluations? This "sandbagging" problem is the #1 unsolved challenge in AI safety evaluation
(UK AISI proved all existing detection methods fail, arXiv:2512.07810). We are developing distributional
methods for detecting strategic underperformance from model outputs alone.
See open questions below.
Combined: 78,631 published evaluations across 4 rigorous studies + ~800 exploratory across 2 additional, 13 frontier models, 8 vendors.
Studies 1-4: all data public, all claims independently verifiable from raw scored records.
Studies 5-6: exploratory scale, raw data archived.
Built on UK AISI Inspect framework.
Tasks from the Adversarial Metacognition Benchmark.